
Elaborazione grafica sulla mappa delle previsioni a 48 ore dell'ECMWF di temperatura dell'aria a 2 metri da terra e velocità del vento a 10 metri da terra basata sui dati di sabato 13 novembre 2021 alle ore 00:00.
Il sogno di Fenwick Cooper era quello di sviluppare un modello matematico per descrivere il moto turbolento dei fluidi, un problema sul quale i fisici si sono scervellati per cento anni. «Mi sono reso conto che non sarei stato io a scoprire questa nuova incredibile teoria». Così Cooper, che oggi collabora con lo European Centre for Medium-Range Weather Forecast (ECMWF), è sceso a compromessi e si è specializzato in modelli numerici della turbolenza, «questo è il percorso che mi ha portato a conoscere e impiegare sistemi di machine learning per descrivere la dinamica dell’atmosfera e degli oceani».
Cooper è l'autore di uno studio su come gli strumenti di machine learning potrebbero migliorare il sistema di previsioni integrato dell'ECMWF sulla temperatura dell'aria e la velocità del vento vicino alla superficie terrestre. Lo studio è stato finanziato al 50% dalla International Foundation Big Data and Artificial Intelligence for Human Development (IFAB) con sede a Bologna ed è stato presentato per la prima volta lo scorso 9 novembre in un seminario online.
Insieme ai colleghi dell'ECMWF, ha adottato un approccio conservativo e ha utilizzato il machine learning per correggere a posteriori le previsioni dell’ECMWF e ottimizzarle rispetto a due variabili specifiche, la temperatura dell’aria a 2 metri di altezza e la velocità del vento a 10 metri di altezza. Ha impiegato diversi tipi di algoritmi di machine learning, da un "semplice" modello di regressione lineare a quelli più complicati, random forest e una rete neurale. Tutti questi strumenti, dopo un'adeguata procedura di allenamento su dati storici, sono stati in grado di migliorare l’accuratezza delle previsioni di temperatura dell’aria e velocità del vento rispetto alle misurazioni effettuate dalla maggior parte delle stazioni meteorologiche sparse sulla superficie terrestre.
Considerando le previsioni per l’inverno 2020-2021, il miglioramento è stato sostanziale sia per le previsioni a poche ore di distanza che per quelle a 48 ore di distanza, e ammonta a circa 0,3°C. In media, cioè aggregando tutte le stazioni meteorologiche, le previsioni dello ECMWF a 48 ore di distanza differiscono dalle misurazioni delle stazioni meteo di circa 2,7°C. Dunque le correzioni a posteriori ottenute con i metodi di machine learning migliorano l’accuratezza di circa il 15%.
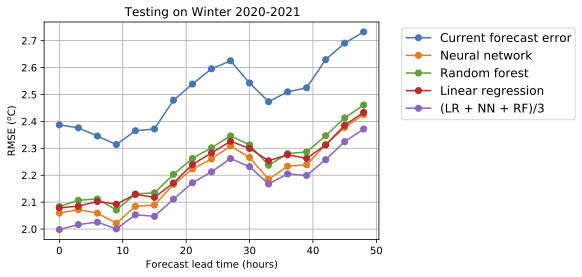
Quando parliamo di differenza tra previsioni e misurazioni, facciamo sempre riferimento alla radice dell’errore quadratico medio. Immaginiamo di prendere una singola stazione meteorologica e di chiedere al modello dell’ECMWF di calcolare le previsioni di temperatura e vento superficiali ogni giorno con diversi orizzonti temporali (previsioni a 3 ore, 6 ore, e così via fino a 48 ore di distanza). Ripetiamo questa procedura per ogni giornata della stagione invernale 2020-2021 (qui intesa come i mesi di dicembre 2020, gennaio e febbraio 2021) e memorizziamo tutte i valori previsti. Ripetiamo lo stesso esercizio usando questa volta il modello dell’ECMWF corretto con gli algoritmi di machine learning. A questo punto confrontiamo le previsioni dei modelli con le misurazioni delle stazioni meteo e ne calcoliamo la differenza. Per ciascuna stazione e ciascun giorno avremo una previsione a 3 ore, una a 6 ore, e così via fino a 48 ore. Sommando il quadrato delle differenze delle previsioni a 3 ore per tutti i giorni e tutte le stazioni e prendendone la radice quadrata, otteniamo una stima dell’accuratezza del modello a 3 ore, il secondo punto del grafico qui sopra. Facendo lo stesso con le previsioni a 6 ore, 9 ore e così via otteniamo il resto dei punti del grafico. Immagine per gentile concessione di Fenwick Cooper.
Facendo le stesse valutazioni stazione per stazione, otteniamo la mappa qui sotto, che mostra come il machine learning migliori le previsioni di temperatura nella maggior parte dei casi.
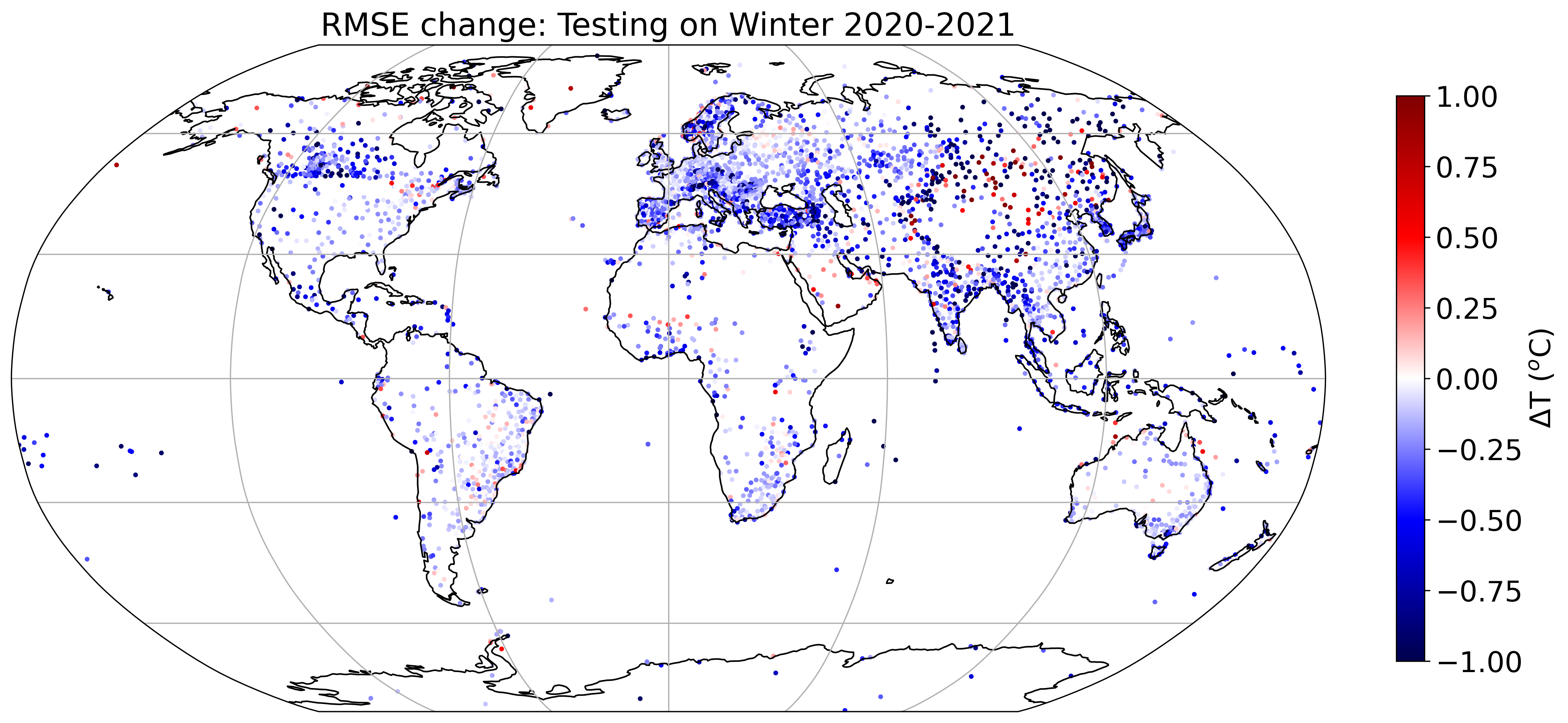
I punti blu indicano le stazioni dove la correzione del machine learning è più importante, quelli rossi le stazioni dove, invece, il machine learning “peggiora” la previsione del modello dell'ECMWF. Immagine per gentile concessione di Fenwick Cooper.
I risultati sulle previsioni della velocità del vento sono più irregolari, anche se in alcune zone, come l’Europa nordoccidentale, l’America sudorientale, l’India e il sudest asiatico il machine learning migliora l’accuratezza in modo sostanziale e dunque in media su tutta la superficie terrestre l’accuratezza migliora di circa 0,2 metri al secondo, sia considerando previsioini a 3 ore che previsioni a 48 ore di distanza. Il miglioramento è quasi il 10% dell’accuratezza attuale. La differenza tra i risultati di temperatura e vento, spiega Cooper, potrebbe essere dovuta al fatto che le misure della velocità del vento sono meno accurate rispetto a quelle dell’aria e dunque è meno facile correggerle.
Questo è solo uno dei molti progetti sul machine learning che lo ECMWF sta portando avanti. Nella Roadmap for machine learning activities at ECMWF pubblicata all'inizio di quest'anno, vengono riconosciute le enormi potenzialità che queste tecniche computazionali offrono al mondo delle previsioni meteo. Allo stesso tempo vengono però sottolineate le sfide poste dall'integrazione di questi algoritmi nel workflow di previsione del centro. Una sfida è integrare i modelli convenzionali, basati cioè sulla descrizione matematica della dinamica delle diverse componenti del sistema Terra, con le diverse tecniche di apprendimento automatico per testarne le performance. Oltre a questo però, c’è in gioco una sfida tecnologica, quella di integrare hardware, architettura dei dati e software.
In una conferenza tenutasi a Oxford nel settembre 2019, riassunta in una edizione dedicata delle Philosophical Transactions A della Royal Society, la comunità delle previsioni meteorologiche si è riunita per discutere quale ruolo potrebbero svolgere i moderni strumenti di apprendimento automatico nelle previsioni meteorologiche. In particolare, parlando di reti neurali profonde, i meteorologi scrivono «la comunità di ricerca meteorologica e climatologica è sempre più consapevole delle moderne tecnologie di deep learning e cerca di adottarle per risolvere specifici problemi di analisi dei dati, modellazione numerica e post-elaborazione nel contesto delle previsioni meteorologiche numeriche. Tuttavia ci sono ancora riserve sul deep learning».
Per vincere queste riserve, l’integrazione dovrà necessariamente essere graduale, come testimoniato dal fatto che il progetto di Cooper ha avuto due obiettivi. «Il primo era quello di scoprire quanto fossero efficaci gli strumenti di apprendimento automatico. Il secondo, e forse il più importante, era capire se qualche parte del modello di previsione dell’ECMWF potesse essere migliorata con metodi convenzionali», dice Cooper. L’idea è di usare il machine learning per ispezionare I modelli convenzionali. «Probabilmente ci sono ragioni culturali dietro questo piano. Molti scienziati all'ECMWF sono fisici di formazione e l'approccio a cui sono abituati è quello di usare leggi fisiche per costruire i modelli. Il machine learning è davvero bravo a raggiungere buone soluzioni, piuttosto che preoccuparsi di capire le cose. Quindi, un modo intelligente per abbinare queste due culture è quello di far fare qualcosa al machine learning e poi cercare di capire cosa sta facendo per aiutare a raffinare i modelli fisici.»
Dietro lo scetticismo dei meteorologi verso le tecniche di machine learning, in particolare le reti neurali profonde, c’è l’impossibilità di spiegarne il funzionamento, cioè di capire quali relazioni causali tra le variabili vengano apprese durante le procedere di allenamento. Il problema della spiegabilità esiste anche in altre aree, come quella della medicina e della salute.
In questo senso è interessante osservare come nel progetto su temperatura dell’aria e velocità del vento, il modello di regressione lineare sembri funzionare tanto bene quanto gli algoritmi più complicati. Questo potrebbe essere un vantaggio proprio in termini di interpretabilità del modello e quindi per capire su quali parti del sistema di previsione ECMWF intervenga e come. «Tuttavia, i modelli lineari che abbiamo usato non sono così semplici come si potrebbe pensare. Abbiamo avuto bisogno di includere fino a quaranta variabili per raggiungere il livello di precisione degli algoritmi di machine learning più sofisticati». Un modello di regressione lineare con quaranta variabili richiede migliaia di coefficienti, un numero di parametri simili a quelli necessari al funzionamento dei due modelli più complessi (random forest e reti neurali). «Con questo numero di variabili, la regressione lineare, alla fine, è difficile da interpretare quanto gli altri modelli.»
Per interpretare i loro risultati, in modo da poter indirizzare i modellisti dell’ECMWF verso un miglioramento, i ricercatori hanno guardato alle correlazioni tra le variabili identificate dagli algoritmi durante la fase di allenamento, che è stata basata su un anno di dati (dal 1^ settembre 2019 al 31 agosto 2020). Hanno visto che le variabili tra cui il modello trovava correlazioni significative riguardano lo stato dell’atmosfera a diversi livelli di altitudine. «Abbiamo intuito che il machine learning di fatto annulla la procedura di interpolazione tra le diverse altitudini seguita dal modello dell'ECMWF e ne effettua una nuova», spiega Cooper.
Questa intuizione è stata confermata guardando alle caratteristiche delle stazioni meteorologiche dove gli algoritmi di machine learning sembrano funzionare peggio. «Le stazioni su cui le correzioni sono state meno soddisfacenti sono quelle posizionate in regioni che contengono terreni ad altitudini molto diverse fra loro», dice Cooper e continua «il modello divide la superficie terrestre in celle di 10 chilometri per 10 chilometri e prevede un’unica temperatura per tutta la cella. Nel formulare la previsione per una stazione meteo in quella cella, il modello deve tenere conto dell’altitudine della stazione, e sembra che il modo in cui lo fa attualmente sia migliorabile». A titolo di esempio, immaginiamo la cella che include il monte Fuji e le aree circostanti mostrata nell’immagine sotto (nella realtà il modello usa celle di minore estensione). Se la stazione si trova nella piana o sulla vetta del monte la temperatura che misurerà è molto diversa e dunque il meccanismo di interpolazione tra altitudini è estremamente rilevante.

Immagine del Monte Fuji scattata dalla Stazione Spaziale Internazionale il 27 maggio 2001. Credit: NASA.
I risultati ottenuti in questo studio hanno usato solo una piccola parte dei dati a disposizione dell’ECMWF. Gli algoritmi di machine learning sono stati calibrati su un anno di dati e ne restano altri quaranta da utilizzare per osservare le potenzialità di queste tecniche e confermare le intuizioni su quali siano le parti del modello del Centro che possono essere migliorate.